
























Jun 17 2025
How One-Piece Flow Improves Quality
There is a phase in the maturation of a manufacturing process where one-piece flow is the key to improving quality. Once the defective rate is low enough, one-piece flow reduces it by up to a factor of 10. The magnitude of the improvement often surprises managers. The cause-and-effect relationship is not obvious, and the literature on manufacturing quality is mute on the subject. We explore it here.
Quality prerequisites for one-piece flow
Imagine a process that is a sequence of 5 operations you perform each one piece at a time. It would be a candidate for one-piece flow, except that it has a yield of 95.5\% at each operation. Then the yield of the whole process is .955^5 = 79.4\%.
 The Leaky Pipe Model
The Leaky Pipe Model
In a leaky-pipe model of this process, you would have to start 100/0.794 = 126 pieces in order to obtain 100 good pieces out. It would happen, for example, if you lost exactly 4.5\% of the pieces at each operation.
This is the kind of simplistic calculations MRP systems do but it’s not real. Instead, at each operation, the production of defectives fluctuates around the rate, and each unit has a 4.5\% probability of being defective. As a consequence, you need inventory buffers between every two operations for production to proceed uninterrupted, which means that you cannot have one-piece flow.
 If, instead, you have a yield of 99.7\% at each operation, it works out to .997^5 = 98.5\% for the whole process, you need to start an average of 100/.985 = 102 pieces, and it corresponds to a 0.3%probability of failure at each operation. In this case, instead of using buffers between operations, defectives are rare enough to run a one-piece flow and start a new unit whenever you lose one at any operation, slightly reducing the takt time to make sure you produce the required quantity within each shift.
If, instead, you have a yield of 99.7\% at each operation, it works out to .997^5 = 98.5\% for the whole process, you need to start an average of 100/.985 = 102 pieces, and it corresponds to a 0.3%probability of failure at each operation. In this case, instead of using buffers between operations, defectives are rare enough to run a one-piece flow and start a new unit whenever you lose one at any operation, slightly reducing the takt time to make sure you produce the required quantity within each shift.
 Defective Replacement
Defective Replacement
If you have 400 minutes of net available work time to produce 100 units, with a yield of 100\% you would run at a takt time of 4 minutes. With a yield of 98.5\%, in order to almost always be able to produce 100 good units in a shift, you need to design your line for 111 units, for a takt time of 3 minutes and 36 seconds. This is buffering with time rather than WIP and, on most days, you will have slack time at the end of the shift.
Yield Tipping Points
There are tipping points for the yield of a manufacturing process beyond which the approach to improvement must change. We know they exist, even when we can’t tell exactly where they are. And not every process crosses these points.
The First Yield Tipping Point
Wherever it may be, there is a tipping point in the yield of your process, above which you can eliminate the WIP buffers and implement one-piece flow. It then enables you to use other tools and methods and make the next order-of-magnitude improvement in quality.
After that point, it’s no longer the identification of root causes within the process that matters most but instead the speedy detection of operational problems like tools breaking or a new operator on the line. Once you know that something has gone wrong, you usually know what to do about it, but it occurs randomly and batch-and-queue operations delay your discovery of the problems.
The next order-of-magnitude improvement in quality performance comes then from moving to one-piece flow with First-In-First-Out (FIFO) sequencing. It is well known that quality improves as a result of converting a sequence of operations to a U-shaped cell. The proportion of defectives traced to the operations in a cell decreases by at least 50%, and we have seen it drop as much as 90%.
The effect of one-piece flow and FIFO in turn levels off at percentages of defectives commonly on the order of 0.1% = 1,000 dppm. It is not by itself able to achieve single-digit dppm rates.
The second tipping point
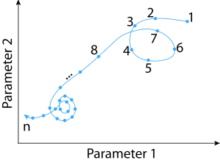
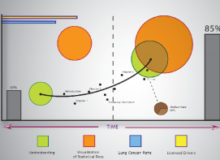
Human error affecting individual parts is still possible, and this is where error-proofing comes in: it is the strategy that takes you from, say, 1,000 dppm to 1 dppm. The following log-log plot summarizes this discussion:

The log-log plot, consistent with learning curve thinking, assumes a fixed drop in defective rates every time the cumulative volume doubles. This is a commonly used inverse-power model for cost reductions. Its math never leads to a negative value, and shows a decreasing rate of improvement that is slow enough that you cannot make an infinite volume with only a finite set of defectives. And it gives you a straight line in a log-log plot.
This plot is not based on a dataset of processes having gone through these phases. It is merely an illustration of the concept that, while their exact locations may vary, there are tipping points beyond which you need different methods to continue improving quality. There is no one-size-fits-all approach.
The skills that are central in the first phase may still be occasionally needed in later phases, as problems with the physics and chemistry of the process never entirely go away, but they are no longer the main engine of improvement. Rapid product obsolescence in high-technology manufacturing companies may prevent them from ever experiencing the later stages.
Lack of process capability
If your main problem is lack of process capability, your percentage of failures will typically be in double digits, and this issue should be addressed ahead of anything else. You do it by applying knowledge of process physics/chemistry, data science, and control technology.
There is empirical evidence that the results of efforts centered on process capability level off around a few percentage points of internally detected defectives. The SPC literature, for example, does not consider what happens when an organization successfully uses its tools. While disruptions from assignable causes rarefy, false alarms from common causes maintain their frequency, and the ratio of true to false alarms drops to a level that destroys the credibility of the alarms.
One-piece flow and First-In-First-Out
Once you have established process capability, the plant faces a change in the nature of quality problems, from drifts in process parameters to infrequently occurring discrete events like tool breakage, skipped steps, or mislabeled components. The challenge at this point is to detect them quickly and react promptly. By definition, you have already solved most of the problems that require an elaborate root cause analysis, and now speed takes precedence over analytical sophistication.

One-piece Flow
The one-piece flow pattern is that, from the time it leaves the input buffer to the time it reaches the output buffer, each part moves individually from step to step without any accumulation of WIP allowed between machines or work stations.
Quality Impact
This has several consequences for quality:
- The lead time through this sequence of operations is an order of magnitude shorter than with batch and queue between every two operations. If you test parts immediately after production, you can feed positive test results back to the line before damaging more pieces.
- Because parts move First-In-First-Out (FIFO) at every step, you preserve the process sequence, and you can identify the parts with any defect detected at testing.
- Within the process, you immediately detect any defect at a step that prevents the successful execution of the next step, preventing the production of further defectives.

You back up the effects of one-piece flow and FIFO with in-process quality checks, with go/no-go gauge checks or with what Shigeo Shingo called “successive inspection” in assembly, where each assembler touches the parts installed by the previous one. Here are a few examples of go/no-go gauges in current use:

For any characteristic, the options are:
- No checking. If you never found a particular dimension out of spec for 10 years, you probably don’t need to check it.
- First and last piece checking. It is applicable to production runs where you can interpolate the characteristics for pieces in between. The checking operations then become part of the setups rather than of production tasks.
- 100% checking. As part of their routines, operators check every part and place defectives in a red box where the quality department collects them.
A throwback to the 1870s?
Quality professionals with SPC training have a hard time accepting these concepts because they exclude both measurements and sampling. Based on their training, they think that you should never use a go/no-go gauge where you can take a measurement, because the measurement is much richer in information.
The measurement tells you more than whether a dimension falls between goal posts; it tells you where. They have also been told that measuring 100% of the parts is unaffordable, and that well-designed sampling plans can give you the same information at a lower cost.
No sampling
Sampling is not allowed inside cells, for several reasons:
- It allows defective parts to wait and accumulate between measurements. This does not serve the objective of detecting and responding to problems quickly.
- It disrupts operations. You choreograph operator jobs as sequences of actions that they repeat with every part. Add measurements on every fifth part at one operation, and you throw off the operator’s routine. On the other hand, you can make a check on every piece a
part of this routine. Then you engineer go/no-go gauges to make these checks fast enough not to slow down production.
Also, given that the problems we are trying to detect are discrete state changes rather than drifts or fluctuations, the information loss due to using go/no-go checks instead of measurements is not as great as it would have been earlier, and is more than made up by application to every part rather than to a sample and by the increased speed of problem detection.
External mandates
Quality departments commonly collect measurements and compile them into control charts to satisfy external mandates. This can still be done without disrupting the flow of production, for example, when parts are finished or while they are between segments of the process executed in cells. Measurements, of course, also have a place in the solution of problems you have detected.
Contiguous Input and Output
One- piece flow and FIFO do not imply and are not always implemented in the form of a U-shaped cell. The U- shape, however. also has an impact on quality, simply because seeing incoming and outgoing parts side-by-side makes operators more conscious of quality issues.

Quality Management with One-Piece Flow
Kazuo Kawashima’s Quick Response Quality Control (QRQC) from Nissan, Sadao Nomura’s Dantotsu quality from Toyota Industrial Vehicles, and Shinichi Sasaki’s JKK from Toyota are all approaches targeted at this situation, and they share similar prescriptions.
Error-proofing
When your main remaining quality problem is operator errors, then clearly the last frontier for improvement is their prevention. But if your main problem is the inability to hold tolerances consistently, spending your resources on error-proofing would be lining up deck chairs while the ship is sinking. Conversely, data science is not much help in the prevention of errors that occur once a year.
Conclusion
We focused this discussion on technical tools. To improve quality, there are, of course, many other issues. Our goal was to position different approaches that are often perceived as being in conflict. We also wanted to draw attention to the middle layer where one-piece flow and FIFO play a central role. Companies that use flow lines and cells know that they improve quality. The quality literature, however, rarely mentions them among the tools to that end.
#onepieceflow, #flowline, #cell,#quality



Jun 25 2025
Update on Data Science versus Statistics
Based on the usage of the terms in the literature, I have concluded that statistics has been subsumed under data science. I view statistics as beginning with a dataset and ending with conclusions, while data science starts with sensors and transaction processing, and ends in data products for end users. Kelleher & Tierney’s Data Science views it the same way, and so do tool-specific references like Gromelund’s R for Data Science, or Zumel & Mount’s Practical Data Science with R.
Brad Efron and Trevor Hastie are two prominent statisticians with a different perspective. In the epilogue of their 2016 book, Computer Age Statistical Inference, they describe data science as a subset of statistics that emphasizes algorithms and empirical validation, while inferential statistics focuses on mathematical models and probability theory.
Efron and Hastie’s book is definitely about statistics, as it contains no discussion of data acquisition, cleaning, storage and retrieval, or visualization. I asked Brad Efron about it and he responded: “That definition of data science is fine for its general use in business and industry.” He and Hastie were looking at it from the perspective of researchers in the field.
Continue reading…
Share this:
Like this:
By Michel Baudin • Data science, Uncategorized • 0 • Tags: data science, math, statistics