Mar 6 2013
Wanna Sabotage Your Lean Implementation Effort? Try This | Lonnie Wilson | IndustryWeek
See on Scoop.it – lean manufacturing
Most facilities that fail in a lean implementation have failed to create stable process flow. And by stable I mean statistically stable — a process that is predictable. (Wanna Sabotage Your #Lean Implementation Effort?
Michel Baudin‘s insight:
The way I read Lonnie’s article, he is saying that neglect of the engineering dimension of Lean manufacturing is the primary cause of implementation failure. I agree. It is a long article, but worth reading.
See on www.industryweek.com

















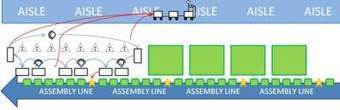
Mar 12 2013
The baton-touch approach
The following question came this morning from Diogo Cardoso:
Your researched the wrong sources. You could have found your answer in Working with Machines, pp. 140-142. Baton-touch is one of three approaches used to design operator jobs in cells, the other two being the caravan/rabbit-chase and bucket-brigades. The key differences are as follows:
Share this:
Like this:
By Michel Baudin • Answers to reader questions • 0 • Tags: Cellular manufacturing, industrial engineering, Lean manufacturing, Manufacturing engineering, Operator job design