
Feb 9 2017
Capacity Planning For 1st-Responders
Early in my consulting career, working with Kei Abe, I was surprised to hear him make seemingly contradictory recommendations about the organization of maintenance in a small auto parts plant and in a large car assembly plant. In both, the managers were thinking of splitting the maintenance group into smaller teams, each dedicated to a production line. In the parts plant, Kei Abe talked them out of it; in car assembly, he supported it. When I asked him why he just said: “the parts plant is too small.”
Contents
A Simplistic Model
Reflecting on this later, I worked out a simple but nonetheless useful model of this situation to help me understand the difference. As Kyle Harshberger pointed out in his comments, it is not just simple but simplistic and underestimates the number of technicians needed. We will return to this issue below. Simplistic though it is, it still makes the point that it is beneficial to split up the maintenance department in some cases but not others.
The Maintenance department in the parts plant had 20 members, which would have been split into 4 groups of 5. Assuming the technicians work in parallel, have the same skills, and that, combining planned and unplanned tasks, are busy 80% of the time. Then they will all be busy simultaneously
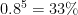
of the time. As a consequence, one equipment failure in three has no technician available to respond. It is not an acceptable level of service.
If instead, the whole plant is served by a central group of 20 technicians, each busy 80% of the time, they will all be busy simultaneously
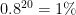
of the time. It means that there is at least one technician available to respond immediately to 99% of the failures, unquestionably better service. With technicians busy only 50% of the time, a subgroup of 7 would have at least one member available 99.3% of the time and, overall, you would have needed 7×4=28 technicians to respond as promptly as the central group with 20.
In the car assembly plant, the Central Maintenance had 300 technicians serving the entire plant, with limited interchangeability, because they served shops like stamping, painting, machining or assembly with different technology. The managers proposing to divide them into 6 groups of 50. If we do the same calculation as above, we find that, in each group of 50, with all technicians busy 80% of the time, they will all be simultaneously busy
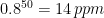
of the time.
As a metric of the effectiveness of the Maintenance department, we could use the probability of having at least one technician available when a machine breaks down, and call it “Responsiveness.” Then the number of technicians needed to achieve a given responsiveness while keeping the technician utilization at a given level would be:

There is, however, a difference between a concept that helps you understand why splitting a maintenance group is a good idea only if the resulting subgroups have a critical mass and a formula that you could apply to determine what this mass is. The key points, relevant to any group that responds to random events, are as follows:
- The group cannot simultaneously be small, efficient, and responsive. The larger the group, the more you are able to keep its members busy with useful work while retaining the ability to respond to events.
- Increasing the size of the group has diminishing returns. In the parts plant case, the difference in responsiveness between 4 groups of 5 and one group of 20 was substantial, between failing to respond on average to one out of every three events and one out of every 100 events. In the car assembly plant, on the other hand, going from 6 groups of 50 to group of 300 meant going from never experiencing a failure to respond in your lifetime to never experiencing it for a millennium.
The managers in both the parts and car assembly plant had a different — and valid — reason to want to distribute maintenance resources among the different shops inside the plant. They wanted the technicians in close contact and constant communication with the production people they supported and reporting to the production managers. They didn’t want the technicians to be strangers dispatched by a distant bureaucracy. But size matters in the extent to which you can pursue this goal.
How To Fix The Simplistic Model
The model is based on taking snapshots of technician availability at different times, noticing, for example, that the number of technicians available to respond to an emergency fluctuates around 4 out of 20 — whether this is due to many failures fixed quickly, or few that take a long time, with planned tasks mixed in. From this, I concluded that each technician has an 80% utilization on these tasks and, therefore, is available to be assigned to a new one 20% of the time. And I did not resist the temptation to simply multiply these utilizations to calculate the probability that all are busy.
The flaw in the reasoning, that Kyle pointed out, is that, when all technicians are busy, it means that there are at least as many machines needing attention as there are technicians, and not exactly as many, which is assumed when multiplying the utilizations. In other words:
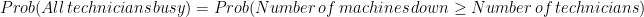
If we assume, for example, that 20 technicians look after 1oo machines, and that, in steady state, an average of 16 require attention. Then the average number of technicians required is 16, giving an 80% utilization. Assuming all machines to be failing independently and at the same rate, we can assume the binomial distribution for the number of machines down at any time and calculate the probability of having at least 20 of them down. In this example, the result is that you would need 26 technicians rather than 20 to bring the probability of all of them being busy at the same time under 1%. You can verify it using the BINOMDIST function in Excel or the dbinom function in R.
In addition, the vision of maintenance as simply dispatching an individual technician whenever a machine breaks down is itself simplistic. The more complex issues encountered in real maintenance include the following:
- Maintenance tasks on large machines often require teams rather than individuals. There is little one person can do alone in the maintenance of a nuclear reactor, a chemical plant, or a steel mill.
- Not all equipment failures are of equal severity. Some put lives at risk, some stop production, and others can be worked around until help is available. In principle, this should be systematically assessed through FMEA (Failure Mode Effect Analysis), but it is not as common a practice as the literature suggests.
- Technicians are generally not fully interchangeable. Even when they are cross-trained on mechanical, piping, electrical power and controls issues, an individual’s familiarity with specific machines and their operators makes a difference.
- …
A Few Conclusions
A comprehensive policy for maintenance in a factory may include the following:
- 5S to maintain an uncluttered, clean and tidy environment for production equipment. From a maintenance standpoint, it rules out many causes of equipment problems.
- Autonomous Maintenance to delegate routine tasks like changing light bulbs and frayed cables to production operators. This frees up maintenance technicians for more complex tasks.
- Systematic reviews of equipment and maintenance specs. This may lead, for example, to replacing machines whose yearly maintenance costs exceeds their replacement cost, eliminating checks on devices that are no longer used, or reinforcing checks on — and re-engineering — devices that have recently failed…
- Cross-training of technicians in the different trades involved in maintenance work, to build a corps of “general practitioners”/first responders who can solve the majority of the problems.
- The assignment of “primary care technicians” by area in the plant, to be called in priority from that area, but backed up by the other technicians when unavailable. The point is to have it both ways: a technician who is familiar with and close to the people he or she is supporting, and technical resources available in an emergency.
- Having higher-level specialists to help with the problems the technicians can’t handle. Depending on circumstances, these may be equipment engineers employed by the company or outside contractors.
The responsiveness discussion above applies to first responders assumed to have the same skills. Not all maintenance work is responding to emergencies. It is a combination of planned and unplanned work but even planned maintenance on a machine takes more or less time depending on what the technicians discover when they open it up. You know when a biyearly check on a machine is planned to start, but not whether it will take a day or a week.
Capacity planning for everything a complete Maintenance Department does is more complex and beyond the scope of this post. Managers can be tempted to apply in maintenance the capacity planning methods that are effective in production. The nature of the work and the objectives pursued, however, are sufficiently different to require a different approach. You plan production work with the objective of keeping each operator busy as close to 100% of the takt time as you can. If you attempt this with maintenance, you will be unresponsive.
#Maintenance, #FirstResponders, #CapacityPlanning, #EmergencyResponse
February 9, 2017 @ 2:01 pm
There is an issue with the calculations, but the direction and spirit of your analysis is accurate. The probability of having no available workers when another machine goes offline is dependent on the number of workers, ratio between the time to complete repairs and the time between machine failures, and (to a lesser extent) the number of machines which can break down.
We can assume a large enough number of machines that all of them do not break down, use your 80% Utilization assumption to take care of the time ratio, and just vary the number of workers using Queueing Theory. If we assume unplanned tasks only and exponentially distributed events:
For n = 5, the probability of all workers unavailable ~55%
For n = 20, ~25%
For n = 100, ~2%
The formula for this uses factorial, so my computer cannot calculate it for n = 300.
Including planned work will make these values worse if the planned work is scheduled without considering the status of the unplanned work.
February 10, 2017 @ 7:06 am
As far as I can tell, the main problem I have had with the math here is getting WordPress to display equations the same way in different browsers…
Emergency response differs from queueing in general in that events require an immediate response. The fire department cannot put fires on a waiting list and, if it does, it is failing. Likewise, if you pull the stop rope on an assembly line that generates $20K/min of revenue, you need an immediate response. And a hospital emergency room where patients wait 13 hours before anyone examines them does not live up to its name.
There are many systems that are expected never to make you wait. When you pick up a phone, you expect a virtual circuit to be immediately allocated to your conversation, and you have a low opinion of any phone system where “all circuits are busy.”
The simplifying assumptions in my post are that technicians work individually and independently of one another, on tasks that cannot be interrupted. A technician who starts work on a machine finishes it before becoming available for anything else. Each technician is just busy or available. Queues are failures of the system, and you want to dimension the department so that they practically never accumulate.
The only thing we need to know about the tasks is that they vary in occurrence times and durations in such a way that the utilization is the probability that a technician is busy at any given time. This is what you observe by work sampling. If, when visiting the maintenance department multiple times, you notice that 80% of the technicians are out on jobs — planned or unplanned — it tells you that each technician has an 80% probability of being busy at any time.
Then it’s a simple multiplication to obtain the probability that they are all busy at the same time. No factorials are needed. Incidentally, if you need to calculate factorials for large numbers, use Stirling’s formula.
February 10, 2017 @ 8:18 am
“The simplifying assumptions in my post are that technicians work individually and independently of one another, on tasks that cannot be interrupted. A technician who starts work on a machine finishes it before becoming available for anything else. Each technician is just busy or available.”
These are the assumptions of queueing theory.
I agree that observing 80% of technicians out on jobs through multiple observations shows that they are working 80% of the time. This holds true for a queueing system as well (PASTA principle). The part that is missing from your calculation is you have assumed there can only be a number of machines broken down at a time as there are total employees.
If a queue forms for emergencies, even though that is a failure, it does not mean it is absent from system. The argument to use queueing theory is about properly modeling the situation, not the desire to have queues. Queues exist because of randomness in the system.
I think there is a misunderstanding of what I am describing as a queueing system. More generally, I would describe an emergency response process as a Markov process with the number of unresolved emergencies as the state. Since the time to resolve an emergency and the time between emergencies are both random, you need to study emergencies as a Markov process. Queueing theory is just a terminology for this.
February 10, 2017 @ 9:12 am
I personally do not have a problem with probability, Markov processes, and queueing theory but it’s a terminology that I try to avoid when communicating with manufacturing people. I have observed that this vocabulary does not get you far with them, and this is why I don’t use it unless absolutely necessary.
The simple math I am using is just to answer one question: at any time, what is the probability of having at least one technician available to respond to a hypothetical emergency. It requires assumptions about the technicians’ work pattern, but not about the process by which emergencies occur.
February 10, 2017 @ 10:05 am
I’m mostly concerned about setting staffing recommendations with this assumption. If % of events that are not serviced immediately is the goal, you will understaff the department with the equations in the post. This is easy to verify through measurement.
If you want a 99% service level like the 20 person, 80% utilization example, you would actually need 26 people (62% utilization) with exponentially distributed events.
February 10, 2017 @ 3:16 pm
I am not recommending using the formula for staffing, because it is based on simplistic assumptions. The key point is the idea that keeping everyone as busy as possible is not always the primary objective. In the post, I explained where my numbers are coming from, and you seem to disagree with the logic. Please explain why, and note that I am making no assumptions about the distribution of the times between emergencies or the times to repair. All I am using is the probability of having at least one technician available, based on their utilization.
February 10, 2017 @ 5:46 pm
You have assumed a Bernoulli process. This ignores the states when there are additional emergencies unmet.
Let’s say there are 6 machines and 5 technicians. There is a >0 probability of having anywhere from 0 to 6 machines currently failing. Without knowing the failure rate or distribution, you cannot calculate the probability of having 0-4 machines down.
If we start from a Bernoulli distribution in 0-5, some of the probability has to move from 0-5 into 6. If it all came from 5, then it would be fine. However to keep generality, it moves out of all of 0-5. This makes the probability of 5 or 6 larger than the probability of just 5 in the original problem. Adding more machines obviously increases the gap from the original problem.
February 11, 2017 @ 7:35 am
I am looking at people, not machines, operating in a steady state. Taking snapshots of technician availability at different times, I notice that the number of technicians who are available to respond to an emergency fluctuates around 4 out of 20, whether this is due to many failures fixed quickly, or few that take a long time, with planned tasks mixed in. However the activity is baked in, the bottom line is that each technician has an 80% utilization on these tasks and is therefore available to be assigned to a new one 20% of the time.
This gives you a binomial distribution for the number of available technicians at any time, with the probability 0.8 for any technician to be busy, and the probability that all are busy is just 0.8 to the power of 20, or 1%.
February 11, 2017 @ 12:37 pm
You can’t separate the technicians from the number of machines because the number of technicians working is dependent on the number of machines which are broken (or whatever other work they are doing). You have to look at the probability distribution of the work.
If you could just look at the number of people, then the binomial distribution would lead to the same result as the Markov process discussed above. Both models have an 80% utilization, but the probability distribution of the number of technicians working at a given time is different.
To extend the 6 machine example, let the probability of a machine being in failure be 68.35%. You can find the binomial distribution of these machine states:
0 0.10%
1 1.30%
2 7.03%
3 20.25%
4 32.79%
5 28.33%
6 10.20%
If you take these values, you find the utilization of the workers is ~80%. The probability of having all workers working is 38.53%, which is greater than the 33% in the example.
If we could separate the technician from the work, these probabilities would be the same.
Saturation In Manufacturing Versus Service | Michel Baudin's Blog
April 2, 2017 @ 9:45 am
[…] Capacity Planning For 1st Responders, we considered the problem of dimensioning a group so that there is at least one member available […]