Nov 22 2016
If Talk Of Probability Makes Your Eyes Glaze Over…
Few terms cause manufacturing professionals’ eyes to glaze over like “probability.” They perceive it as a complicated theory without much relevance to their work. It is nowhere to be found in the Japanese literature on production systems and supply chains, or in the American literature on Lean. Among influential American thinkers on manufacturing, Deming was the only one to focus on it, albeit implicitly, when he made “Knowledge of Variation” one of the four components of his System of Profound Knowledge (SoPK).
Contents
Probability in the Literature on Manufacturing
Otherwise, any discussions of probability in the manufacturing literature are limited to the statistical approach to quality — from the 1930’s SPC to the 1980s Six Sigma — and to academic Operations Research (OR).Introduction to Operations Research, a textbook commonly used in business schools, had 75 pages on probability theory in its 1980 edition, but no longer does in its 2014 edition. Factory Physics has 7-pages on “Basic Probability” as an appendix to its Chapter 2, on Inventory Control. These primers may be fine for graduate students, but no manufacturing professional I have ever met would read them.
What is odd is that the same manufacturing professionals who say they have no use for probability theory complain next about fickle customers, suppliers who can’t reliably deliver on time, machines that stop, and uneven operator performance… exactly the kind of issues this theory is intended to address. It was developed specifically to help people deal with randomness and risk in a rational fashion, as explained in an entertaining manner by Peter L. Bernstein in Against the Gods.
In fact, probability theory is a body of knowledge with potential contributions in manufacturing, that is underutilized for lack of communication between mathematicians with no knowledge or respect for manufacturing, and manufacturing experts disinclined to learn the math. In the age of data science, it is particularly unfortunate, because the alternative to thinking in terms of probabilities is to rely on common sense and intuition, which leads you astray.
Common Misconceptions
Following are a few examples of the most common misconceptions.
Independence
If you toss a fair coin, whether it comes up heads or tail, the odds of having heads or tail on the next toss will still be 50/50. Everyone will agree that it is true. This is a simple concept, easily explained, but counter-intuitive in its consequences. In the most general formulation, events are independent if the outcome of one does not change probabilities for the other.
Most people’s intuition tells them that, after observing a streak of heads, the next toss is more likely to produce a tail. The coin, however, doesn’t know it has just produced a streak of heads and is under no compulsion to produce a tail next. Others will believe that the streak is too unlikely for a fair coin, and that they were lied to. But streaks happen with no cheating involved.
Simulating 300 independent fair coin tosses takes a few seconds with Excel. In one simulation, I got 149 heads and 151 tails, which was consistent with equal odds, but, in that sequence, were a streak of 6 consecutive heads and another of 7 consecutive tails, all signifying nothing, and not influencing in any way the outcome of the following tosses.
The misunderstanding of the concept of independence was best illustrated by cartoonist Jacques Roussel’s Shadoks, birds who designed a rocket so badly that it only had one chance in a million to fly. The Shadoks were in a great hurry to fail 999,999 times, so that the rocket would fly on the millionth attempt.



What does this have to do with manufacturing? Some devices or machine components have failure rates that do not change over time. Every day, they have the same probability of failing, and the failures occur independently, so that what happens today is not influenced in any way by what happened yesterday or the day before.
It is equally likely to fail the day after you install the component as 10 years later. The counter-intuitive consequence is that there is nothing to be gained by replacing the component periodically, because the new one is just as likely to fail tomorrow as the old one. You should just let it run until it fails. What contingency plan you put in place to deal with its eventual failure depends on the consequences. It ranges from having a redundant part pre-installed that automatically goes into action when the current one fails to ordering the part after the failure.
Random sampling
Random sampling means selecting a sample from a population in such a way that each sample has a predetermined probability of being picked. The most common case is when each member of the population has an equal probability of being selected. It is not always the right thing to do. For example, if you pick a sample among orders received within a month with an equal selection probability for each, you will not see any change in customer behavior due to day of the month.
Likewise, if you take a random sample from the output of a machine tool, you will not see the effect of tool wear. There are, however, many statistical procedures whose validity is predicated on random sampling. But how do you do it? Intuition tells you to ask an operator to pick here and there “at random” from a bin of parts. Anyone who has taken an initiation course in statistics knows that this does not produce a random sample. In the field, you encounter quality engineers who are trained in statistical methods and still make that mistake, perhaps encouraged by the Google definition describing a random sample as “chosen without method or conscious decision.”
If you physically tumble the parts in a drum like lottery balls, you may be able to pull a genuinely random sample. Otherwise, you need a system to generate random numbers and tell you which unit to pick next. The first consequence of not sampling randomly is that you invalidate the formulas used to determine a confidence interval or to decide whether to accept a batch if these formulas assume random sampling.
When you receive raw materials mined out of the ground, scrap metal for recycling, or drums of oil for cosmetics compounding, you need to test samples to determine their composition, adjust your processes accordingly, or reject them, and many procedures can introduce biases, like, for example, always picking from the most convenient location.
This is similar to surveys based on recipients who volunteer to answer, or people who can be reached by land telephone lines as opposed to cell phones, etc. There are many sensible ways to organize sampling, but the decision of what to pick within the population should not be left up to the individuals who execute the sampling. It must be part of the decision process, and specified by its designer.

Series of Events
If you maintain a machine, you find that it runs for long stretches, separated by failures that appear to arrive all at once. Similarly, if you spend an afternoon in a retail store, you get the definite impression that customers arrive in clusters separated by dry stretches. Your intuition tells you that there is some sort of underlying cause for clusters of equipment failures or customer arrivals. The theory tells you that independent events occurring at a constant average rate have many short times between events and a few, occasional long times, which creates the appearance of clustering in the absence of any clustering mechanism.
Sample bias can lead to dramatic mistakes, as in the example of damage patterns in returning aircraft in World War II. The military wanted to reinforce the parts that had been hit. After plotting the bullet hole patterns, however, statistician Abraham Wald concluded that the parts of the aircraft that needed reinforcing were the ones that showed no damage on the returning aircraft — the cockpit and the engines — because this is where the aircraft that had not returned had been hit.
Tolerance stacking
The conventional wisdom of engineers is that, if you join three rods cut to lengths that are within ±0.001in of target, the joined rod is within ±0.003in.

If, however, the deviations from target on each of the three rods are equally likely to be in either direction, and to compensate for each other when you join the rods. The tolerance limits are upper and lower bounds for the deviations, and are not additive. In statistical tolerancing, you use a probabilistic model of the deviations to establish that the tolerance you are capable of holding on the joint rod is in fact 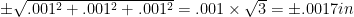
Gambler’s Ruin
If the odds are against you, even slightly, your best chance of winning is to bet everything you have on a single move. The odds are still against you, but playing small, “prudent” moves only makes them worse. If you take a look at a casino roulette wheel, you find that it has 37 slots, of which 18 are red and 18 black, with the green 0 slot making all the difference.
If you bet red, or black, the odds are 1.055 to 1 against you, and, because of this, the best strategy is to bet all your chips at once and walk away. It is counter-intuitive and not much fun, and probability theory proves to you that no other strategy will improve your chances. Gamblers either don’t know it or willfully ignore it but casinos don’t, as it is the basis for their business.
If gamblers were rational and well informed, Las Vegas would still be a desert. In business, the odds of beating a dominant competitor are against you, and attrition hopeless. Your only chance is bold play, which is what Steve Jobs did when he returned to Apple in 1997.
#probability, #manufacturing, #operationsresearch, #lean, #deming
Probability For Professionals | Michel Baudin's Blog
January 3, 2017 @ 10:29 am
[…] a previous post, I pointed out that manufacturing professionals’ eyes glaze over when they hear the word […]