Dec 23 2011
How to achieve a lean transformation
Via Scoop.it – lean manufacturing
The Manufacturing Digital ezine devotes an entire section to Lean, and this is the latest entry. It is more about what needs to be done than how to do it. In the featured picture, the executives look like the marines on Iwojima, but they also seem about to jump off a cliff.
Via www.manufacturingdigital.com




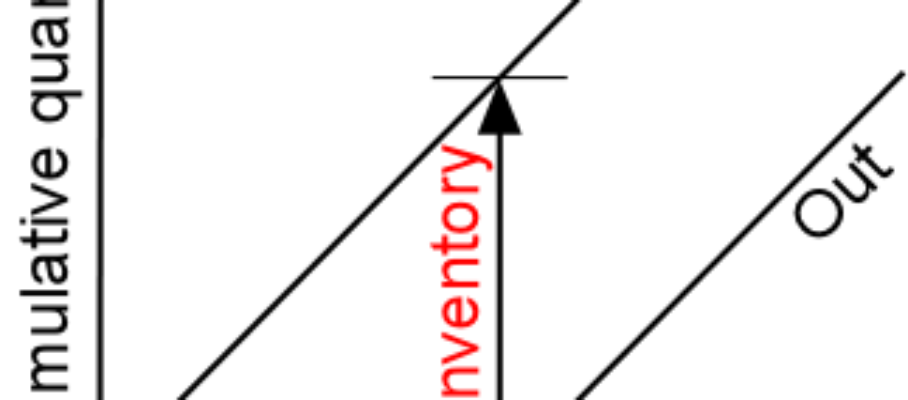


Feb 5 2012
Should Governments Subsidize Manufacturing Consultants?
Since 1988, the federal government of the United States has been subsidizing consulting firms through a program called Manufacturing Extension Partnership (MEP) out of the National Institute of Standards and Technology (NIST). The MEP has existed through five presidencies of both parties and now supports 1,300 consultants who provide cut-rate services to small and medium-size manufacturing companies, effectively shutting out other consultants from this market segment.
This raises the question of what qualifies an agency set up to calibrate measurement instruments to pick winners among consultants in areas like technology acceleration, supplier development, sustainability, workforce and continuous improvement. Clearly, the leaders of the MEP must have an extensive experience of manufacturing to make such calls.
Director Roger Kilmer just posted an article entitled A Blueprint for America: American Manufacturing on the NIST MEP blog. According to his official biography, the director of the MEP has been with NIST since 1974 and has never worked in manufacturing. On the same page, you can see that some members of the MEP management team have logged a few years in the private sector, in electric utilities, nuclear power, and IT services. None mention anything like 20 years in auto parts or frozen foods.
I agree with Roger Kilmer that manufacturing is essential to the growth of the U.S. economy, and even that government should help. All over the world, particularly at the local level, governments provide all sorts of incentives for companies to build plants in their jurisdiction. But is it proper for a government to directly subsidize service providers? The alternative is that whatever help is given go directly to manufacturing companies, for them to pay market rates for services from providers they choose.
In addition, the most effective help is not necessarily a subsidy. Hearing the CEO of a small, French manufacturing company uncharacteristically praise then finance minister Christine Lagarde, I asked what she had done to deserve it. “In 2009,” he said, “banks were denying credit to everybody. We were going bust. She decreed that bankers had to explain why for each case to her ministry. That was enough to pry the money loose.” It was done with a light touch, didn’t cost any money, and worked.
Share this:
Like this:
By Michel Baudin • Management • 3 • Tags: Government, Management, Manufactuting