Feb 8 2012
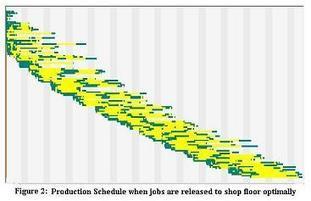
Graphic representation of a Lean schedule
Via Scoop.it – lean manufacturing
A clever graphic tool. According to the author, Prasad Velaga, the schedule was actually generated by finite capacity scheduling logic from a real test dataset that was taken from a job shop.
Via optisol.biz

Dec 1 2022
About Digital Twins
Some hosts showed digital twins during the Van of Nerds tour de France last September, but none mentioned the cyber-physical systems touted as a key component in Industry 4.0. Furthermore, we also found that the meaning of digital twin had drifted away from detailed simulations of physics and chemistry as part of a cyber-physical system for process control.
Instead, a digital twin is now an animation of part movements and machine status in a line for production control. This has effectively disabled discussions of digital twins in the context of cyber-physical systems, which matters in stabilizing and establishing capability for high-technology processes like additive manufacturing.
Continue reading…
Contents
Share this:
Like this:
By Michel Baudin • Van of Nerds • 3 • Tags: cyber-physical system, digital twin, Process capability, process control, Production control