The first question we usually ask about lead times, inventory levels, critical dimensions, defective rates, or any other quantity that varies, is what it is “on the average.” The second question is how much it varies, but we only ask it if we get a satisfactory answer to the first one, and we rarely do.
When asked for a lead time, people usually give answers that are either evasive like “It depends,” or weasel-worded like “Typically, three weeks.” The beauty of a “typical value” is that no such technical term exists in data mining, statistics, or probability, and therefore the assertion that it is “three weeks” is immune to any confrontation with data. If the assertion had been that it was a mean or a median, you could have tested it, but, with “typical value,” you can’t.
For example, if the person had said “The median is three weeks,” it would have had the precise meaning that 50% of the orders are delivered in less than 3 weeks, and that 50% take longer. If the 3-week figure is true, then the probability of the next 20 orders all taking longer, is . This means that, if you do observe a run of 20 orders with lead times above 3 weeks, you know the answer was wrong.
In Out of the Crisis, Deming was chiding journalists for their statistical illiteracy when, for example, they bemoaned the fact that “50% of the teachers performed beneath the median.” In the US, today, the meaning of averages and medians is taught in Middle School, but the proper use of these tools does not seem to have been assimilated by adults.
One great feature of averages is that they add up: the average of the sum of two variables is the sum of their averages. If you take two operations performed in sequence in the route of a product, and consider the average time required to go through these operations by different units of product, then the average time to go through operations 1 and 2 is the sum of the average time through operation 1 and the average time through operation 2, as is obvious from the way an average is calculated. If you have n values
the average is just
What is often forgotten is that most other statistics are not additive.
To obtain the median, first you need to sort the data so that . For each point, the sequence number then tells you how many other points are under it, which you can express as a percentage and plot as in the following example:
Graphically, you see the median as the point on the x-axis where the curve crosses 50% on the y-axis. To calculate it, if n is odd, you take the middle value
and, if n is even, you take the average of the two middle values, or
and it is not generally additive, and neither are all the other statistics based on rank, like the minimum, the maximum, quartiles, percentiles, or stanines.
An ERP system, for example, will add operation times along a route to plan production, but the individual operation times input to the system are not averages but worst-case values, chosen so that they can reliably be achieved. The system therefore calculates the lead time for the route as the sum of extreme values at each operation, and this math is wrong because extreme values are not additive. The worst-case value for the whole route is not the sum of the worst-case values of each operation, and the result is an absurdly long lead time.
In project management, this is also the key difference between the traditional Critical Path Method (CPM) and Eli Goldratt’s Critical Chain. In CPM, task durations set by the individuals in charge of each task are set so that they can be confident of completing them. They represent a perceived worst-case value for each task, which means that the duration for the whole critical path is the sum of the worst-case values for the tasks on it. In Critical Chain, each task duration is what it is actually expected to require, with a time buffer added at the end to absorb delays and take advantage of early completions.
That medians and extreme values are not additive is experienced, if not proven, by a simple simulation in Excel. Using the formula “LOGNORM.INV(RAND(),0,1)” will give you in about a second, 5,000 instances of two highly skewed variables, X and Y, as well as their sum X+Y. On a logarithmic scale, their histograms look as follows:
And the summary statistics show the Median, Minimum and Maximum for the sum are not the sums of the values for each term:
Averages are not only additive but have many more desirable properties, so why do we ever consider medians? There are real problems with averages, when taken carelessly:
Averages are affected by extreme values. It is illustrated by the Bill Gates Walks Into a Bar story. Here we inserted him into a promotional picture of San Fancisco’s Terroir Bar:Attached to each patron other than Bill Gates is a modest yearly income. But his presence pushes the average yearly income above $100M, which is not a meaningful summary of the population. On the other hand, consider the median. Without Bill Gates, the middle person is Larry, and the median yearly income, $46K. Add Bill Gates, and the median is now the average of Larry and Randy, or $48K. The median barely budged! While, in this story, Bill Gates is a genuine outlier, manufacturing data often have outliers that are the result of malfunctions, as when wrong measurements are recorded as a result of a probe failing to touch the object it is measuring, or the instrument is calibrated in the wrong system of units, or a human operator puts a decimal point in the wrong place…Large differences between average and median are a telltale sign of this kind of phenomenon. Once the outliers are identified, assessed, and filtered, you can go back to using the average rather than the median.
Averages are meaningless over heterogeneous populations. The statement that best explains this is “The average American has exactly one breast and one testicle.” It says nothing useful about the American population. In manufacturing, when you consider, say, a number of units produced, you need to make sure you are not commingling 32-oz bottles with minuscule free samples.
Averages are meaningless for multiplicative quantities. If you data is the sequence of yields of the n operations in a route, then the overall yield is , and the plain average of the yields is irrelevant. Instead, you want the geometric mean.
The same logic applies to the compounding of interest rates, and the plain average of rates over several years is irrelevant.
Sometimes, averages do not converge when the sample size grows. It can happen even with a homogeneous population, it is not difficult to observe, and it is mind boggling. Let us say your product is a rectangular plate. On each one you make, you measure the differences between their actual lengths and widths and the specs, as in the following picture:
Assume then that, rather than the discrepancies in length and width, you are interested in the slope ΔW/ΔL and calculate its average over an increasing number of plates. You are then surprised to find that, no matter how many data points you add, the ratio keeps bouncing around instead of converging as the law of large numbers has led you to expect. So far, we have looked at the averages as just a formula applied to data. To go further, we must instead consider that they are estimators of the mean of an “underlying distribution” that we use as a model of the phenomenon at hand. Here, we assume that the lengths and widths of the plates are normally distributed around the specs. The slope ΔW/ΔL is then the ratio of two normal variables with 0 mean, and therefore follows the Cauchy distribution. This distribution has the nasty property of not having a mean, as a consequence of which the law of large numbers does not apply. But it has a median, which is 0.
The bottom line is that you should use averages whenever you can, because you can do more with them than with the alternatives, but you shouldn’t use them blindly. Instead, you should do the following:
Clean your data.
Identify and filter outliers.
Make sure that the data represents a sufficiently homogeneous population.
Use geometric means for multiplicative data.
Make sure that averaging makes sense from a probability standpoint.
Mar 17 2014
Averages in Manufacturing Data
The first question we usually ask about lead times, inventory levels, critical dimensions, defective rates, or any other quantity that varies, is what it is “on the average.” The second question is how much it varies, but we only ask it if we get a satisfactory answer to the first one, and we rarely do.
When asked for a lead time, people usually give answers that are either evasive like “It depends,” or weasel-worded like “Typically, three weeks.” The beauty of a “typical value” is that no such technical term exists in data mining, statistics, or probability, and therefore the assertion that it is “three weeks” is immune to any confrontation with data. If the assertion had been that it was a mean or a median, you could have tested it, but, with “typical value,” you can’t.
For example, if the person had said “The median is three weeks,” it would have had the precise meaning that 50% of the orders are delivered in less than 3 weeks, and that 50% take longer. If the 3-week figure is true, then the probability of the next 20 orders all taking longer, is . This means that, if you do observe a run of 20 orders with lead times above 3 weeks, you know the answer was wrong.
. This means that, if you do observe a run of 20 orders with lead times above 3 weeks, you know the answer was wrong.
In Out of the Crisis, Deming was chiding journalists for their statistical illiteracy when, for example, they bemoaned the fact that “50% of the teachers performed beneath the median.” In the US, today, the meaning of averages and medians is taught in Middle School, but the proper use of these tools does not seem to have been assimilated by adults.
One great feature of averages is that they add up: the average of the sum of two variables is the sum of their averages. If you take two operations performed in sequence in the route of a product, and consider the average time required to go through these operations by different units of product, then the average time to go through operations 1 and 2 is the sum of the average time through operation 1 and the average time through operation 2, as is obvious from the way an average is calculated. If you have n values
the average is just
What is often forgotten is that most other statistics are not additive.
To obtain the median, first you need to sort the data so that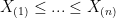 . For each point, the sequence number then tells you how many other points are under it, which you can express as a percentage and plot as in the following example:
. For each point, the sequence number then tells you how many other points are under it, which you can express as a percentage and plot as in the following example:
Graphically, you see the median as the point on the x-axis where the curve crosses 50% on the y-axis. To calculate it, if n is odd, you take the middle value
and, if n is even, you take the average of the two middle values, or
and it is not generally additive, and neither are all the other statistics based on rank, like the minimum, the maximum, quartiles, percentiles, or stanines.
An ERP system, for example, will add operation times along a route to plan production, but the individual operation times input to the system are not averages but worst-case values, chosen so that they can reliably be achieved. The system therefore calculates the lead time for the route as the sum of extreme values at each operation, and this math is wrong because extreme values are not additive. The worst-case value for the whole route is not the sum of the worst-case values of each operation, and the result is an absurdly long lead time.
In project management, this is also the key difference between the traditional Critical Path Method (CPM) and Eli Goldratt’s Critical Chain. In CPM, task durations set by the individuals in charge of each task are set so that they can be confident of completing them. They represent a perceived worst-case value for each task, which means that the duration for the whole critical path is the sum of the worst-case values for the tasks on it. In Critical Chain, each task duration is what it is actually expected to require, with a time buffer added at the end to absorb delays and take advantage of early completions.
That medians and extreme values are not additive is experienced, if not proven, by a simple simulation in Excel. Using the formula “LOGNORM.INV(RAND(),0,1)” will give you in about a second, 5,000 instances of two highly skewed variables, X and Y, as well as their sum X+Y. On a logarithmic scale, their histograms look as follows:
And the summary statistics show the Median, Minimum and Maximum for the sum are not the sums of the values for each term:
Averages are not only additive but have many more desirable properties, so why do we ever consider medians? There are real problems with averages, when taken carelessly:
The same logic applies to the compounding of interest rates, and the plain average of rates over several years is irrelevant.
Assume then that, rather than the discrepancies in length and width, you are interested in the slope ΔW/ΔL and calculate its average over an increasing number of plates. You are then surprised to find that, no matter how many data points you add, the ratio keeps bouncing around instead of converging as the law of large numbers has led you to expect. So far, we have looked at the averages as just a formula applied to data. To go further, we must instead consider that they are estimators of the mean of an “underlying distribution” that we use as a model of the phenomenon at hand. Here, we assume that the lengths and widths of the plates are normally distributed around the specs. The slope ΔW/ΔL is then the ratio of two normal variables with 0 mean, and therefore follows the Cauchy distribution. This distribution has the nasty property of not having a mean, as a consequence of which the law of large numbers does not apply. But it has a median, which is 0.
The bottom line is that you should use averages whenever you can, because you can do more with them than with the alternatives, but you shouldn’t use them blindly. Instead, you should do the following:
As Kaiser Fung would say, use your number sense.
Share this:
Like this:
By Michel Baudin • Data science • 8 • Tags: Average, Bill Gates walks into a bar, Critical Chain, Deming, ERP, Goldratt, mean, median, typical value